

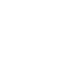

Figure 1: Evolution of computing technology
As computing technology evolved, technologists tried various permutations and combinations to achieve a computing solution featuring







Figure 2: Edge analytics high level overview
1. Device Edge: These are the devices running on-premises at the edge, such as cameras, sensors, and other physical devices that gather data or interact with sensor data. Simple edge devices gather or transmit data, or both. The more complex edge devices have the processing power to do additional activities. In both cases, it is important to be able to deploy and manage the applications on these edge devices. Examples of such applications include image/video analytics, deep learning AI models, and simple real-time processing applications.
2. Local Edge: These are systems running on-premises or at the edge of the network. The edge network layer and edge cluster/servers can be separate physical or virtual servers existing in various physical locations, or they can be combined in a hyperconverged system. There are two primary sublayers to this architecture layer. Both the components of the systems that are required to manage these applications in these architecture layers as well as the applications on the device edge, will reside here.
3. Cloud: This architecture layer is generically referred to as the cloud but it can run on-premises or in the public cloud. This layer is the source for workloads, which are applications that need to handle the processing that is not possible at the other edge nodes and the management layers. Workloads include application and network workloads that are to be deployed to different edge nodes by using the appropriate orchestration layers.
Depending on the application, one of the following approaches can be considered for the implementation of edge analytics.
Intelligently ingesting data from edge-based equipment and machines, even without constant Internet connectivity, and sending data to cloud-based analytical software whenever an Internet connection is available. Intelligent edge ingesting focuses on pulling only the most critical data. The data then goes to a cloud-based repository where cloud analytics can be performed, with results pushed back to the edge or to centralized reporting workflows. The key technical challenges in this process include accessing and ingesting sensor values, buffering data, and monitoring the connectivity.
Performing rules-based analytics (formulabased calculations) locally, using simple formula-based calculations can be performed before sensor values leave an edge location. Compute rules may be installed or created on edge hardware, so data is locally analyzed as it is acquired. The outputs of such calculations may then be streamed to the cloud, similar to raw sensor values, or used locally, depending on the use case. The computing hardware requirements for this type of solution are relatively cheap and minimal.
Performing advanced analytics, computeintensive operations such as machine learning algorithms, or advanced simulations locally. This requires various levels of analytics at the edge and in the cloud. Better use of local sensor data often requires analytics beyond simple rules-based calculations. However, deploying machine learning models or compute-intensive simulation analytics to the edge (for instance, to classify or detect abnormal equipment behavior in real time) can be challenging.
An integrated solution that can ingest data from local sensors and deploy, store, and run cloudbased analytical models at the edge is often the best option. Of course, depending on the complexity and compute intensity of advanced models at the edge, the local computing hardware requirements may be significantly different from the relatively lightweight requirements for streaming data or performing simpler calculations.
The following factors need to be considered while designing an Edge Analytics solution:

Figure 3: Model training and deployment
Edge Analytics consists of two major workflows:

To build a new Edge Analytics solution, we can use readily available algorithms via Azure Machine Learning, Amazon SageMaker®, or open source frameworks such as TensorFlow®, Apache MXNet, PyTorch™, etc., to build and train machine learning models. Tools such as Amazon SageMaker Neo, TensorFlow Lite, Apache TVM, Microsoft's ONNX runtime, NVIDIA® TensorRT, Intel® OpenVINO®, STM32Cube.AI, etc., enable deployment of optimized deep learning and machine learning models on edge hardware. Azure and AWS platforms also support leading open source ML frameworks, and these models can be used with Azure IoT Edge or AWS Greengrass for ML inference at the edge.
Major cloud vendors have collaborated with semiconductor companies to deliver AI chips. Microsoft collaborated with Qualcomm to develop Vision AI DevKit, which uses Azure ML to develop the models, and Azure IoT Edge to deploy the models to the kit as containerized Azure services. Qualcomm’s Neural Processing SDK can be used to optimize the models and to improve the performance further. Similarly, in collaboration with Intel, Amazon has developed DeepLens, a wireless camera with AI inferencing capability. It can be integrated with Amazon’s SageMaker Data Science platform. Google’s Coral with Edge Tensor Processing Units (TPUs) provides a toolkit to train TensorFlow models and deploy them on different platforms using the Coral USB Accelerator.

Robotic Surgery
Robotic surgery is gaining popularity today due to advantages such as minimized pain, precise cuts/operations, faster recovery time, and the unique capability of operating and monitoring robotic surgery remotely. It enables doctors to perform surgeries from various locations without any travel or the need to be physically present. This is beneficial for both surgeons as well as patients.
Edge analytics plays a vital role in robotic surgery equipment. The major components involved are robotic arms with precise movement control and high-resolution camera with depth sensor. The system performs all its movements considering a reference point. The edge computer gets inputs from camera, doctor’s instructions, and current position of the arms. After receiving this data, a pretrained AI model processes all this input data and calculates the destination position and angles of the robotic arms using reverse kinematics.
Once the movement path data is available, corresponding movement commands are given to the robotic arms. Arm movements are continuously monitored by the edge computer using the motor feedback data and camera— open loop and closed loop control systems. If any dynamic obstacle appears in the movement path, the movement path will be recalculated and new path commands will be issued to the robotic arms. The edge computer also needs to have backup safety mechanism and a safe state of operation.
All these operations need to happen in real time with very small latency, in milliseconds. Due to the type of application and its time criticalness, most of the decision-making and monitoring activities are performed by the edge computer. The events, reports, and recorded logs are transmitted to the cloud. In case of remote surgery, live video-frames get transferred through a high-speed secured Internet channel like 5G or broadband.

Autonomous Driving and Smart Infrastructure for Efficient Mobility
Autonomous driving capability is a special edge computing case, as significant compute power is necessary to run the driving algorithms in real time within the control unit in the vehicle. The usage of edge analytics can also be found in smart infrastructures such as 5G base stations, traffic lights, or intermediate smart routers. This enables much higher efficiency and throughput at intersections.
Take the case of a complex and heavily used intersection with five roads and long waiting times for each vehicle at the traffic lights. Autonomous driving alone would not eliminate waiting times, as it respects the timing of the traffic lights. But when an edge node is installed at the intersection to which the vehicles connect when approaching the intersection, they can receive their trajectories from the edge node. This edge node can do an orchestration of all the nearby vehicles instead of separate computation of each vehicle.
If this solution is then extended to include charging planning for electric vehicles, mobility can become even more efficient. The edge node at the charging station would then be able to plan upcoming charging processes and optimize the reservations according to various criteria, including waiting time or maximum charging rate.
Adaptive Predictive Maintenance
Automotives of the future will be known for their performance and high driver engagement. The battery in these vehicles with an electric drive needs to deliver this at its possible best. To achieve this, battery monitoring and predictive maintenance are essential.
Battery maintenance and charging depends on dynamic situations (tire pressure, acceleration, traffic, charge cycles, driver habits), when the car is actually running on the road. Better optimized performance and mileage can be achieved by analyzing and processing usage data, which is not available at the time of production.
Edge computing can enable this with the ability to aggregate data and near-real-time evaluation of relevant battery parameters and sensor values. As this has a direct impact on customer experience, it is highly relevant for car manufacturers and car network providers with electric vehicles in their fleets.

There are several use cases for edge analytics across industries:

Amol Gharpure, Senior Solution Architect – Healthcare and Life Sciences, has 16+ years of embedded product development experience in the medical domain.

Vishwanath Pratap Singh, Industry Offering Head, Healthcare and Life Sciences, works with large number of customers to understand the business context and provide optimal and customized solutions.







