
In the last few years artificial intelligence(AI) algorithms and machine learning (ML) approaches have been successfully applied in real-world scenarios such as commerce, industry, and digital services, but they are not widespread in software testing and networking. Most AI/ML applications in software testing remain academic due to the complexity of software. This paper briefly presents the state of the art in the field of software testing applying ML approaches and AI algorithms. The progress analysis of AI and ML methods used for this over the last three years is based on the Scopus Elsevier, Web of Science, and Google Scholar databases. Algorithms used in software testing have been grouped by test types. The paper also tries to corelate the main AI approaches and which type of tests they are applied to, in particular white-box, grey-box, and black-box software testing. We conclude that black-box testing is, by far, the preferred method of software testing when AI is applied. Also, all three methods of ML (supervised, unsupervised, and reinforcement) are commonly used in black-box testing being the “clustering” technique. Opportunities abound to apply artificial intelligence (AI) and machine learning to networking. Use cases such as network automation and resource optimization can help network operators reduce cumbersome manual processes (thereby increasing efficiency) in network testing and operations and provide more and better services to their customers.
AI is a new field of endeavor for many operators, however, and crucial design decisions need to be made about inputs and outputs, hardware and software, machine- learning models, model training, and deployment.
.png?width=1000&height=667&name=MicrosoftTeams-image_(20).png)
Figure 1. Artificial intelligence is the foundation of an intelligent network.
This white paper attempts to answer some of these questions and describes how standards bodies are working to integrate AI and machine learning into networking and testing. It also explains some of the technology offerings that can help maximize AI performance for a given use case. Using this information, operators can begin or accelerate their network testing and operations and AI journey.
Network testing is the chief way of validating a network against the defined requirements, and accounts for about half of the development cost and time. It is argued that improvements in network infrastructure could save up to a third of its costs. On the other hand, in the last few decades, the concepts of artificial intelligence (AI) and machine learning (ML) have been successfully used to explore the potentialities of data in different fields. ML is used to teach machines how to handle the data more efficiently, simulating the learning concept of the rational beings, and can be implemented with AI algorithms (or techniques) reflecting the paradigms/approaches of rational characteristics as connections, genetic, statistical and probabilities, case-based, etc. With AI algorithms, and based on the ML approach, it is possible to explore and extract information in order to classify, associate, optimize, cluster, forecast, and identify patterns, etc.
AI techniques provide predictive models to be used for multiple engineering purposes, but it is still not a popular implementation for checking systems under test (SUT) correctness. It seems logical to apply AI in software testing; however, the lack of a mechanism to distinguish correct and incorrect SUT behavior is currently a bottleneck. AI is rarely used so far for error detection in SUT because of the lack of automation of problems. The exception is regression testing where the correct performance of the SUT can be derived from its previous version behavior.
Industry is abuzz about the possibility of having a machine-learning system continuously monitoring and controlling the network. Tractica reports that the telecom industry is expected to invest USD 36.7 billion annually in AI software, hardware, and services by 2025. Another survey revealed that 63.5% of operators are investing in AI systems to improve their infrastructure.
Standards bodies are steadily working to improve the integration of AI and machine learning into network architecture. For example, 3GPP has introduced the 5G Network Data Analytics Function (NWDAF). This function collects network data from other network functions and performs data analysis that can help improve 5G network management automation. The O-RAN Alliance introduced the radio access network (RAN) intelligent controller (RIC), which is a cloud-native, microservices-based function that collects data and customizes RAN functionality using AI and machine-learning algorithms.

It is known that AI techniques provide predictive models to be used for multiple engineering purposes, but it is still not a popular implementation for checking systems under test (SUT) correctness. In theory, AI for network operations (AIOps) should be able to maximize service assurance and infrastructure utilization, flattering just about every key performance indicator (KPI) for the network operator. Figure 1 provides an end-to-end pipeline view of an AIOps system.
AIOps can be applied to network automation, resource optimization, and many other areas. For example, self- optimizing networks (SONs) are a tantalizing goal for network operators. However, to achieve AIOps, operators must answer some important questions. This white paper discusses some considerations network architects should explore as they begin their AIOps journey.
AI systems work by receiving input data, analyzing that data using one or more models, and producing outputs. For telecommunications network architects, identifying appropriate inputs is crucial to developing an AI system that can deliver on the promise of AI for 5G network operation and optimization. Once those inputs are identified, if some of them are not currently available, steps must be taken to make them available. For example, new data collection tools, or access to data external to the network might be needed.
In contrast to 4G networks, 5G networks make extensive use of network slicing. This approach virtualizes the network to create virtual connections that provide different resources to different types of traffic, which in turn have different quality of service (QoS) requirements. This poses a challenge for AIOps because the AI system must merge all relevant KPIs and forecast them into a single service-level objective (SLO) that is appropriate for each network slice.
The following list suggests possible inputs from the network itself
5G networks contain many network performance metrics across different network elements. Examples include physical layer signal quality measurements, Layer 2 data transmission statistics, and Layer 3 radio link connection and mobility metrics.
Gathering performance metrics from network functions and microservices can help monitor and predict overall network performance. This information can be related to compute, storage, and networking resources. For example, resource director technology (RDT) brings new levels of visibility and control over how shared resources such as last-level cache (LLC) and memory bandwidth are used by applications, virtual machines (VMs), and containers. This level of detail can help ensure the accuracy of the AIOps system.
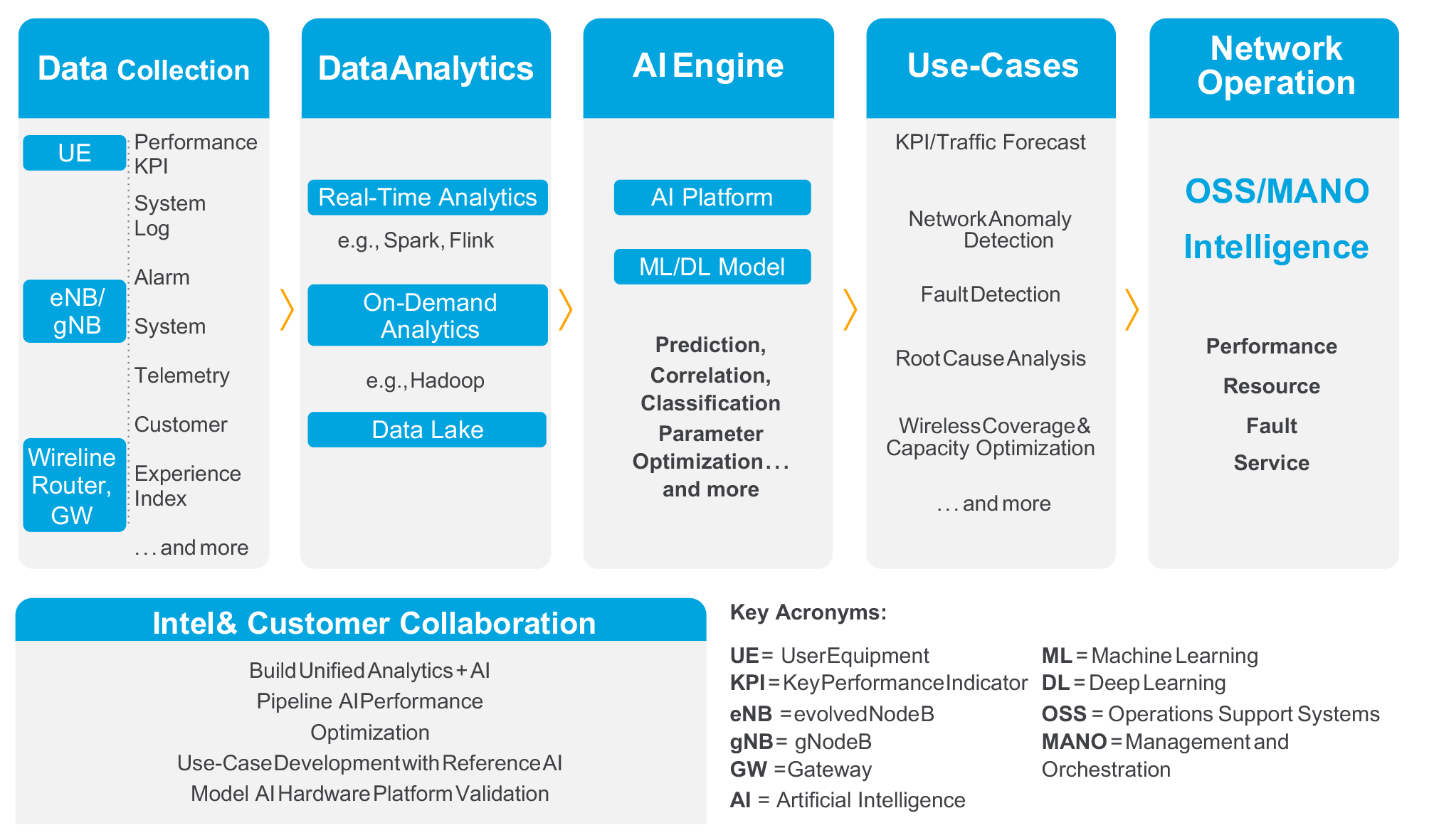 Figure 2. From data collection to taking action, an artificial intelligence for operations (AIOps) system has many stages
Figure 2. From data collection to taking action, an artificial intelligence for operations (AIOps) system has many stages
The AIOps system requires visibility into which functions and microservices are moving data—and how much data. Given a particular SLO, the system can apply this metric to use machine learning inference to increase network efficiency.
Another source of information for AIOps includes network alarms and fault metrics. This information can be used to predict failures or bottlenecks.
Data can be current (such as in the last 15 minutes) or historical (such as the last seven days’ worth of a certain metric). Adding historical data to the time-series prediction model is called a “memory augmented” model, and can help improve a model’s accuracy, especially when attempting to predict things such as sudden changes in network quality or spikes in the number of users.
Beyond data that is inherent to the network, the AIOps system can be enriched by external sources of data. This could include the date, time of day, weather, geographical region, specific location of user, buffering ratio, and so on. By combining network data, service and application data, and customer data, network operators have a good starting point to create a powerful AIOps system.
Another aspect of gathering inputs relates to how often the inputs are collected. The answer depends on which part of the network architecture is being automated or optimized. For the core network, interference decisions and enforcement might be based on measurements taken every 15 minutes. In contrast, the RAN might take measurements through a management user interface every few seconds, with a goal of less-than-one-second latency for predictions and inference decisions. 5G RAN central units (CUs) and distributed units (DUs) might need even faster control, down to less than 10 ms.
The output of an AIOps system depends on the use case. The following subsections discuss potential outputs for network automation and resource optimization.
Certain outputs from the AIOps system can be injected back into the network functions. It is important to identify which outputs these are, and into which network functions they should be injected. The general usage model is for network operators to use KPIs to predict what is going on, and take appropriate action based on comparing the present value to the predicted value. For example, if the utilization of a cell is decreasing, the operator can shut down some antennas to save energy. The AIOps system uses critical analysis and/or reinforcement learning to choose the right action based on the use case.
Specifically what the outputs are depends on the aspect of the network. For example, the outputs for the operations support systems (OSS) and business support systems (BSS) differ from those for the RIC and the NWDAF. As AIOps evolves, automated policies are increasingly applied to these control points. Operators and solution providers around the world are conducting trials and proofs of concept to further evolve network automation.
Another use case is resource optimization. This can be done for quality of experience (QoE) and/or QoS. For resource- intensive, latencysensitive applications such as cloud-based virtual reality (VR), AI can replace traditional QoS policies to provide a better experience to users. The right AI model can help predict dynamic traffic volume and fluctuating radio transmission capabilities and can inform closedloop network optimization (configuration changes and application of various policies) in near-real time. In other usages, traffic congestion could lead to degradation of service for all users. AI can be used to enforce QoS policies for certain prioritized users, giving them a satisfactory level of service even if other users’ QoS is lower.

There are a lot of choices for machine-learning models. These include convolutional neural networks (CNNs), recurrent neural networks (RNNs)—long short-term memory (LSTM) networks—and neuromorphic networks. All these models work differently and do different things; so how does a network operator make the right decision?
For 5G RAN, models based on time series prediction can be applied to the majority of RAN functions. But other models for prediction are emerging. These new models may be a combination of CNN and RNN layers and are suitable in use cases such as beamforming optimization and the network scheduler. Another model, called multilayer perceptron (MLP), is a class of feedforward artificial neural network (ANN) and could be a good choice for classification prediction and regression prediction use cases. Reinforcement learning is often used for network configuration optimization.
One guiding rule for choosing a model for a use case is the required model accuracy. For example, in the case of choosing to shut down base station antennas to save energy during low-utilization periods (such as at night time), the forecast accuracy needs to be high— otherwise, customer experience will suffer. But other use cases may not have such strict accuracy requirements.
Beyond the probability that an inference will be correct, an equally important—and rarely mentioned—aspect of model accuracy is how far off the mark erroneous inferences are. If there is an error, it could be minor or catastrophic. This becomes more critical as AI control moves from advisory to unsupervised.

Typically, an operator starts with predictive analysis (using time series forecasting), then moves to prescriptive analysis as the AIOps system matures. That is, if a problem is found, the AIOps system can automatically root cause it and choose an action. The end goal is fully automated configuration and network policies enabled by reinforcement learning that does not depend on having a training dataset. Rather, “learning” is accomplished by trying different behaviors/decisions and choosing which ones produce the most positive effect.
The field of AIOps is growing and changing quickly. New use cases and new models are constantly being developed. Investing in a highly skilled data scientist can help operators keep up with advancements and avoid making costly (time or money) mistakes as they build out their AIOps systems.
One important note about AIOps system design must ensure dynamic network control—whether core network, the RIC, or the NWDAF—by deploying AI that is flexible and a service-based architecture that uses microservices (which differs from traditional data center AI workloads). Supervised learning, unsupervised learning, and (deep) reinforcement learning modules should be deployed independent of each other, increasing the utility and flexibility of the AIOps system.
All AI models must be trained before they can be of use. In some industries, the training data might come from a publicly available source, such as airline flight data or world-wide disease infection rates. However, the network data necessary to train an AIOps system typically comes from the operator itself. In some cases, operators can collaborate to “raise all boats” and share certain types of network data to train models. Data can also be anonymized and shared with the model vendor, so that the model can be trained off-premises.
Model training is compute-intensive, and it is imperative that operators invest in the hardware (and optimized software) that can provide the performance necessary for a particular use case. Second and third generation Intel Xeon scalable processors, featuring Intel DL Boost with VNNI can help to accelerate training. Also, since an AIOps system spans the RIC and the core NWDAF to the OSS/BSS in the data center, training also must incorporate data from all these network aspects.


Akhil Pasha, Solutions Architect
Akhil Pasha is a BE in electronics and communications with 16 years of experience in telecommunications and networking. He focuses on data science, analytics, and network management systems. Akhil specializes in building end-toend development integration, and deployment and operationalization of telecom and network applications in fault, capacity, accounts and performance management systems.
![shutterstock_1648661566 [Converted]](https://www.cyient.com/hs-fs/hubfs/shutterstock_1648661566%20%5BConverted%5D.jpg?width=13000&height=7312&name=shutterstock_1648661566%20%5BConverted%5D.jpg)




